Diferencia entre revisiones de «Fairness and bias correction in Machine Learning»
(→Fairness criteria in classification problemsSolon Barocas; Moritz Hardt; Arvind Narayanan, Fairness and Machine Learning, http://www.fairmlbook.org, 2019.) |
(→Other fairness criteria) |
||
| Línea 99: | Línea 99: | ||
== Other fairness criteria == | == Other fairness criteria == | ||
| − | The following criteria can be understood as measures of the three definitions given on the first section, or a relaxation of them. In | + | The following criteria can be understood as measures of the three definitions given on the first section, or a relaxation of them. In the following table we can see the relationships between them. |
Now let us define all this measures specifically: | Now let us define all this measures specifically: | ||
Revisión de 18:16 15 dic 2019
Spanish version: Equidad y corrección de sesgos en Aprendizaje Automático
Work in progress.
Contenido
Fairness criteria in classification problems[1]
In classification problems, an algorithm learns a function to predict a discrete characteristic ![]() , the target variable, from known characteristics
, the target variable, from known characteristics ![]() . We model
. We model ![]() as a discrete random variable which encodes some characteristics contained or implictly encoded in
as a discrete random variable which encodes some characteristics contained or implictly encoded in ![]() that we consider as sensitive characteristics (gender, ethnicity, sexuality, etc.). We finally denote by
that we consider as sensitive characteristics (gender, ethnicity, sexuality, etc.). We finally denote by ![]() the prediction of the classifier.
Now let us define three main criteria to evaluate if a given classifier is fair, that is, if its predictions are influenced by some of this sensitive variables.
the prediction of the classifier.
Now let us define three main criteria to evaluate if a given classifier is fair, that is, if its predictions are influenced by some of this sensitive variables.
Independence
We say the random variables ![]() satisfy independence if the sensitive characteristics
satisfy independence if the sensitive characteristics ![]() are statistically independent to the prediction
are statistically independent to the prediction ![]() , and we write
, and we write ![]() .
.
We can also express this notion with the following formula:
This means that the probability of being classified by the algorithm in each of the groups is equal for two individuals with different sensitive characteristics.
Yet another equivalent expression for equivalence can be given using the concept of mutual information between random variables, defined as
In this formula, ![]() is the entropy of the random variable. Then
is the entropy of the random variable. Then ![]() satisfy independence if
satisfy independence if ![]() .
.
A possible relaxation of the indepence definition include introducing a positive slack ![]() and is given by the formula:
and is given by the formula:
Finally, another possible relaxation is to require ![]() .
.
Separation
We say the random variables ![]() satisfy separation if the sensitive characteristics
satisfy separation if the sensitive characteristics ![]() are statistically independent to the prediction
are statistically independent to the prediction ![]() given the target value
given the target value ![]() , and we write
, and we write ![]() .
.
We can also express this notion with the following formula:
This means that the probability of being classified by the algorithm in each of the groups is equal for two individuals with different sensitive characteristics given that they actually belong in the same group (have the same target variable).
Another equivalent expression, in the case of a binary target rate, is that the true positive rate and the false positive rate are equal (and therefore the false negative rate and the true negative rate are equal) for every value of the sensitive characteristics:
Finally, a possible relaxation of the given definitions is the difference between rates to be a positive number lower than a given slack ![]() , instead of equals to zero.
, instead of equals to zero.
Sufficiency
We say the random variables ![]() satisfy sufficiency if the sensitive characteristics
satisfy sufficiency if the sensitive characteristics ![]() are statistically independent to the target value
are statistically independent to the target value ![]() given the prediction
given the prediction ![]() , and we write
, and we write ![]() .
.
We can also express this notion with the following formula:
This means that the probability of actually being in each of the groups is equal for two individuals with different sensitive characteristics given that they were predicted to belong to the same group.
Relationships between definitions
Finally, we sum up some of the main results that relate the three definitions given above:
- If
 and
and 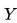 are not statistically independent, then sufficiency and independence cannot both hold.
are not statistically independent, then sufficiency and independence cannot both hold.
- Assumming is binary, if and are not statistically independent, and
 and are not statistically independent, then independence and separation cannot both hold.
and are not statistically independent, then independence and separation cannot both hold.
- If
 as a joint distribution has positive probability for all its possible values and and are not statistically independent, then separation and sufficiency cannot both hold.
as a joint distribution has positive probability for all its possible values and and are not statistically independent, then separation and sufficiency cannot both hold.
Metrics[2]
Most statistical measures of fairness rely on different metrics, so we will start by defining them. When working with a binary classifier, both the predicted and the actual classes can take two values: positive and negative. Now let us start explaining the different possible relations between predicted and actual outcome:
- True positive (TP): The case where both the predicted and the actual outcome are in the positive class.
- True negative (TN): The case where both the predicted and the actual outcome are in the negative class.
- False positive (FP): A case predicted to be in the positive class when the actual outcome is in the negative one.
- False negative (FN): A case predicted to be in the negative class when the actual outcome is in the positive one.
This relations can be easily represented with a confusion matrix, a table which describes the accuracy of a classification model. In this matrix, rows and columns represent instances of the predicted and the actual cases, respectively.
By using this relations, we can define multiple metrics which can be later used to measure the fairness of an algorithm:
- Positive predicted value (PPV): the fraction of positive cases which were correctly predicted out of all the positive predictions. It is usually referred to as precision, and represents the probability of a positive prediction to be right. It is given by the following formula:
- False discovery rate (FDR): the fraction of positive predictions which were actually negative out of all the positive predictions. It represents the probability of a positive prediction to be wrong, and it is given by the following formula:
- Negative predicted value (NPV): the fraction of negative cases which were correctly predicted out of all the negative predictions. It represents the probability of a negative prediction to be right, and it is given by the following formula:
- False omission rate (FOR): the fraction of negative predictions which were actually positive out of all the negative predictions. It represents the probability of a negative prediction to be wrong, and it is given by the following formula:
- True positive rate (TPR): the fraction of positive cases which were correctly predicted out of all the positive cases. It is usually referred to as sensitivity or recall, and it represents the probability of the positive subjects to be classified correctly as such. It is given by the formula:
- False negative rate (FNR): the fraction of positive cases which were incorrectly predicted to be negative out of all the positive cases. It represents the probability of the positive subjects to be classified incorrectly as negative ones, and it is given by the formula:
- True negative rate (TNR): the fraction of negative cases which were correctly predicted out of all the negative cases. It represents the probability of the negative subjects to be classified correctly as such, and it is given by the formula:
- False positive rate (FPR): hte fraction of negative cases which were incorrectly predicted to be positive out of all the negative cases. It represents the probability of the negative subjects to be classified incorrectly as positive ones, and it is given by the formula:
Other fairness criteria
The following criteria can be understood as measures of the three definitions given on the first section, or a relaxation of them. In the following table we can see the relationships between them.
Now let us define all this measures specifically:
References
- ↑ Solon Barocas; Moritz Hardt; Arvind Narayanan, Fairness and Machine Learning, http://www.fairmlbook.org, 2019.
- ↑ Sahil Verma; Julia Rubin, Fairness Definitions Explained, (IEEE/ACM International Workshop on Software Fairness, 2018).