Diferencia entre revisiones de «Equidad y corrección de sesgos en Aprendizaje Automático»
m (→Reweighing Faisal Kamiran; Toon Calders, Data preprocessing techniques for classification without discrimination. Consultado el 17 de Diciembre de 2019) |
(→Separation) |
||
| Línea 28: | Línea 28: | ||
Por último, otra posible relajación pasa por requerir <!-- <math display="inline"> I(R,A) \leq \epsilon </math> --> [[File:IndependenceRel2.JPG|1000x1000px|frameless]]. | Por último, otra posible relajación pasa por requerir <!-- <math display="inline"> I(R,A) \leq \epsilon </math> --> [[File:IndependenceRel2.JPG|1000x1000px|frameless]]. | ||
| − | === | + | === Separación === |
| − | + | Decimos que las [[wikipedia:es:variables aleatorias | variables aleatorias]] <!-- <math display="inline">(R,A,Y)</math> --> [[File: R,A,Y.JPG|1000x1000px|frameless]] satisfacen la separación si las características protegidas <!-- <math display="inline"> A </math> --> [[File: A.JPG|1000x1000px|frameless|text-bottom]] son [[wikipedia:es:independencia (probabilidad)|estadísticamente independientes]] a la predicción <!-- <math display="inline"> R </math> --> [[File: R.JPG|1000x1000px|frameless|text-bottom]] dado el valor objetivo <!-- <math display="inline"> Y </math> --> [[File: Y.JPG|1000x1000px|frameless|text-bottom]], y escribimos <!-- <math display="inline"> R \bot A | Y </math> --> [[File: RbotAbarY.JPG|1000x1000px|frameless]]. | |
| − | + | También podemos expresar esta noción con la siguiente fórmula: | |
<!-- <math display="block"> P(R = r | Y = q, A = a) = P(R = r | Y = q, A = b) \quad \forall r \in R \quad q \in Y \quad \forall a,b \in A </math> --> | <!-- <math display="block"> P(R = r | Y = q, A = a) = P(R = r | Y = q, A = b) \quad \forall r \in R \quad q \in Y \quad \forall a,b \in A </math> --> | ||
[[File: SeparationDef.JPG|1000x1000px|frameless|center]] | [[File: SeparationDef.JPG|1000x1000px|frameless|center]] | ||
| − | + | Esto significa que la [[wikipedia:es:teoría de la probabilidad | probabilidad]] de ser clasificado por el algoritmo en cada uno de los grupos es la misma para dos individuos con características protegidas distintas dado que ambos pertenecen al mismo grupo (tienen la misma variable objetivo). | |
| − | + | Otra expresión equivalente, en el caso de tener una variable objetivo binaria, es la que exige que la [[#Métricas | tasa de verdaderos positivos]] y la [[#Métricas | tasa de falsos positivos]] sean iguales (y por tanto la [[#Métricas | tasa de falsos negativos]] y la [[#Métricas | tasa de verdaderos negativos]] también lo sean) para cada valor de las características protegidas: | |
<!-- <math display="block"> P(R = 1 | Y = 1, A = a) = P(R = 1 | Y = 1, A = b) \quad \forall a,b \in A </math> --> | <!-- <math display="block"> P(R = 1 | Y = 1, A = a) = P(R = 1 | Y = 1, A = b) \quad \forall a,b \in A </math> --> | ||
[[File: SeparationDef1.JPG|1000x1000px|frameless|center]] | [[File: SeparationDef1.JPG|1000x1000px|frameless|center]] | ||
| Línea 43: | Línea 43: | ||
[[File: SeparationDef2.JPG|1000x1000px|frameless|center]] | [[File: SeparationDef2.JPG|1000x1000px|frameless|center]] | ||
| − | + | Por último, una posible relajación de las definiciones dadas es que la diferencia entre tasas sea un número positivo menor que una cierta variable <!-- <math display="inline> \epsilon > 0 </math> --> [[File: EpsMq0.JPG|1000x1000px|frameless]], en lugar de igual a cero. | |
=== Sufficiency === | === Sufficiency === | ||
Revisión de 20:45 17 dic 2019
Versión en inglés: Fairness and bias correction in Machine Learning
En aprendizaje automático, un algoritmo es justo, o tiene equidad si sus resultados son independientes de un cierto conjunto de variables que consideramos sensibles y no relacionadas con él (p.e.: género, raza, orientación sexual, etc.).
Contenido
Criterios de equidad en problemas de clasificación[1]
En problemas de clasificación, un algoritmo aprende una función para predecir una característica discreta ![]() , la variable objetivo, a partir de unas características conocidas
, la variable objetivo, a partir de unas características conocidas ![]() . Modelizamos
. Modelizamos ![]() como una variable aleatoria que codifica algunas características contenidas o implícitamente codificadas en
como una variable aleatoria que codifica algunas características contenidas o implícitamente codificadas en ![]() que consideramos características protegidas (género, etnia, orientación sexual, etc.). Por último, denotamos por
que consideramos características protegidas (género, etnia, orientación sexual, etc.). Por último, denotamos por ![]() la predicción del clasificador.
Ahora pasamos a definir tres criterios principales para evaluar si un clasificador es justo, es decir, si sus predicciones no están influenciadas por algunas de las variables protegidas.
la predicción del clasificador.
Ahora pasamos a definir tres criterios principales para evaluar si un clasificador es justo, es decir, si sus predicciones no están influenciadas por algunas de las variables protegidas.
Independencia
Decimos que las variables aleatorias ![]() satisfacen la independencia si las características protegidas
satisfacen la independencia si las características protegidas ![]() son estadísticamente independientes a la predicción
son estadísticamente independientes a la predicción ![]() , y escribimos
, y escribimos ![]() .
.
También podemos expresar esta noción con la siguiente fórmula:
Esto significa que la probabilidad de ser clasificado por el algoritmo en cada uno de los grupos es la misma para dos individuos con características protegidas distintas.
Se puede dar otra noción equivalente de independencia utilizando el concepto de información mutua entre variables aleatorias, definida como
En esta fórmula, ![]() es la entropía de la variable estadística. Entonces
es la entropía de la variable estadística. Entonces ![]() satisface independencia si
satisface independencia si ![]() .
.
Una posible relajación de la definición de independencia pasa por la introducción de una variable positiva ![]() , y viene dada por la fórmula:
, y viene dada por la fórmula:
Por último, otra posible relajación pasa por requerir ![]() .
.
Separación
Decimos que las variables aleatorias ![]() satisfacen la separación si las características protegidas
satisfacen la separación si las características protegidas ![]() son estadísticamente independientes a la predicción
son estadísticamente independientes a la predicción ![]() dado el valor objetivo
dado el valor objetivo ![]() , y escribimos
, y escribimos ![]() .
.
También podemos expresar esta noción con la siguiente fórmula:
Esto significa que la probabilidad de ser clasificado por el algoritmo en cada uno de los grupos es la misma para dos individuos con características protegidas distintas dado que ambos pertenecen al mismo grupo (tienen la misma variable objetivo).
Otra expresión equivalente, en el caso de tener una variable objetivo binaria, es la que exige que la tasa de verdaderos positivos y la tasa de falsos positivos sean iguales (y por tanto la tasa de falsos negativos y la tasa de verdaderos negativos también lo sean) para cada valor de las características protegidas:
Por último, una posible relajación de las definiciones dadas es que la diferencia entre tasas sea un número positivo menor que una cierta variable ![]() , en lugar de igual a cero.
, en lugar de igual a cero.
Sufficiency
We say the random variables ![]() satisfy sufficiency if the sensitive characteristics
satisfy sufficiency if the sensitive characteristics ![]() are statistically independent to the target value
are statistically independent to the target value ![]() given the prediction
given the prediction ![]() , and we write
, and we write ![]() .
.
We can also express this notion with the following formula:
This means that the probability of actually being in each of the groups is equal for two individuals with different sensitive characteristics given that they were predicted to belong to the same group.
Relationships between definitions
Finally, we sum up some of the main results that relate the three definitions given above:
- If
 and
and 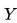 are not statistically independent, then sufficiency and independence cannot both hold.
are not statistically independent, then sufficiency and independence cannot both hold.
- Assumming is binary, if and are not statistically independent, and
 and are not statistically independent either, then independence and separation cannot both hold.
and are not statistically independent either, then independence and separation cannot both hold.
- If
 as a joint distribution has positive probability for all its possible values and and are not statistically independent, then separation and sufficiency cannot both hold.
as a joint distribution has positive probability for all its possible values and and are not statistically independent, then separation and sufficiency cannot both hold.
Métricas[2]
La mayoría de medidas de equidad dependen de diferentes métricas, de modo que comenzaremos por definirlas. Cuando trabajamos con un clasificador binario, tanto la clase predicha por el algoritmo como la real pueden tomar dos valores: positivo y negativo. Empecemos ahora explicando las posibles relaciones entre el resultado predicho y el real:
- Verdadero positivo (TP): Cuando el resultado predicho y el real pertenecen a la clase positiva.
- Verdadero negativo (TN): Cuando el resultado predicho y el real pertenecen a la clase negativa.
- Falso positivo (FP): Cuando el resultado predicho es positivo pero el real pertenece a la clase negativa.
- Falso negativo (FN): Cuando el resultado predicho es negativo pero el real pertenece a la clase positiva.
Estas relaciones pueden ser representadas fácilmente con una matriz de confusión, una tabla que describe la precisión de un modelo de clasificación. En esta matriz, las columnas y las filas representan instancias de las clases predichas y reales, respectivamente.
Utilizando estas relaciones, podemos definir múltiples métricas que podemos usar después para medir la equidad de un algoritmo:
- Valor predicho positivo (PPV): la fracción de casos positivos que han sido predichos correctamente de entre todas las predicciones positivas. Con frecuencia, se denomina como precisión, y representa la probabilidad de que una predicción positiva sea correcta. Viene dada por la siguiente fórmula:
- Tasa de descubrimiento de falsos (FDR): la fracción de predicciones positivas que eran en realidad negativas de entre todas las predicciones positivas. Representa la probabilidad de que una predicción positiva sea errónea, y viene dada por la siguiente fórmula:
- Valor predicho negativo (NPV): la fracción de casos negativos que han sido predichos correctamente de entre todas las predicciones negativas. Representa la probabilidad de que una predicción negativa sea correcta, y viene dada por la siguiente fórmula:
- Tasa de omisión de falsos (FOR): la fracción de predicciones negativas que eran en realidad positivas de entre todas las predicciones negativas. Representa la probabilidad de que una predicción negativa sea errónea, y viene dada por la siguiente fórmula:
- Tasa de verdaderos positivos (TPR): la fracción de casos positivos que han sido predichos correctamente de entre todos los casos positivos. Con frecuencia, se denomina como exhaustividad, y representa la probabilidad de que los sujetos positivos sean clasificados correctamente como tales. Viene dada por la fórmula:
- Tasa de falsos negativos (FNR): la fracción de casos positivos que han sido predichos de forma errónea como negativos de entre todos los casos positivos. Representa la probabilidad de que los sujetos positivos sean clasificados erróneamente como negativos, y viene dada por la fórmula:
- Tasa de verdaderos negativos (TNR): la fracción de casos negativos que han sido predichos correctamente de entre todos los casos negativos. Representa la probabilidad de que los sujetos negativos sean clasificados correctamente como tales, y viene dada por la fórmula:
- Tasa de falsos positivos (FPR): la fracción de casos negativos que han sido predichos de forma errónea como positivos de entre todos los casos negativos. Representa la probabilidad de que los sujetos negativos sean clasificados erróneamente como positivos, y viene dada por la fórmula:
Other fairness criteria

The following criteria can be understood as measures of the three definitions given on the first section, or a relaxation of them. In the table[1] to the right we can see the relationships between them.
To define this measures specifically, we will divide them into three big groups as done in Verma et al.[2]: definitions based on predicted outcome, on predicted and actual outcomes, and definitions based on predicted probabilities and actual outcome.
We will be working with a binary classifier and the folowing notation: ![]() refers to the score given by the classifier, which is the probability of a certain subject to be in the positive or the negative class.
refers to the score given by the classifier, which is the probability of a certain subject to be in the positive or the negative class. ![]() represents the final classification predicted by the algorithm, and its value is usually derived from
represents the final classification predicted by the algorithm, and its value is usually derived from ![]() , for example will be positive when
, for example will be positive when ![]() is above a certain threshold.
is above a certain threshold. ![]() represents the actual outcome, that is, the real classification of the individual and, finally,
represents the actual outcome, that is, the real classification of the individual and, finally, ![]() denotes the sensitive attributes of the subjects.
denotes the sensitive attributes of the subjects.
Definitions based on predicted outcome
The definitions in this section focus on a predicted outcome ![]() for various distributions of subjects. They are the simplest and most intuitive notions of fairness.
for various distributions of subjects. They are the simplest and most intuitive notions of fairness.
- Group fairness, also referred to as statistical parity, demographic parity, acceptance rate and benchmarking. A classifier satisfies this definition if the subjects in the protected and unprotected groups have equal probability of being assigned to the positive predicted class. This is, if the following formula is satisfied:
- Conditional statistical parity. Basically consists in the definition above, but restricted only to a subset of the attributes. With mathematical notation this would be:
Definitions based on predicted and actual outcomes
This definitions not only consider de predicted outcome ![]() but also compare it to the actual outcome
but also compare it to the actual outcome ![]() .
.
- Predictive parity, also referred to as outcome test. A classifier satisfies this definition if the subjects in the protected and unprotected groups have equal PPV. This is, if the following formula is satisfied:
- Mathematically, if a classifier has equal PPV for both groups, it will also have equal FDR, satisfying the formula:
- False positive error rate balance, also referred to as predictive equality. A classifier satisfies this definition if the subjects in the protected and unprotected groups have aqual FPR. This is, if the following formula is satisfied:
- Mathematically, if a classifier has equal FPR for both groups, it will also have equal TNR, satisfying the formula:
- False negative error rate balance, also referred to as equal opportunity. A classifier satisfies this definition if the subjects in the protected and unprotected groups have equal FNR. This is, if the following formula is satisfied:
- Mathematically, if a classifier has equal FNR for both groups, ti will also have equal TPR, satisfying the formula:
- Equalized odds, also referred to as conditional procedure accuracy equality and disparate mistreatment. A classifier satisfies this definition if the subjects in the protected and unprotected groups have equal TPR and equal FPR, satisfying the formula:
- Conditional use accuracy equality. A classifier satisfies this definition if the subjects in the protected and unprotected groups have equal PPV and equal NPV, satisfying the formula:
- Overall accuracy equality. A classifier satisfies this definition if the subject in the protected and unprotected groups have equal prediction accuracy, that is, the probability of a subject from one class to be assigned to it. This is, if it satisfies the following formula:
- Treatment equality. A classifier satisfies this definition if the subjects in the protected and unprotected groups have an equal ratio of FN and FP, satisfying the formula:

Definitions based on predicted probabilities and actual outcome
These definitions are based in the actual outcome ![]() and the predicted probability score
and the predicted probability score ![]() .
.
- Test-fairness, also known as calibration or matching conditional frequencies. A classifier satisfies this definition if individuals with the same predicted probability score
 have the same probability to be classified in the positive class when they belong to either the protected or the unprotected group:
have the same probability to be classified in the positive class when they belong to either the protected or the unprotected group:
- Well-calibration. It's an extension of the previous definition. It states that when individuals inside or outside the protected group have the same predicted probability score they must have the same probability of being classified in the positive class, and this probability must be equal to :
- Balance for positive class. A classifier satisfies this definition if the subjects constituting the positive class from both protected and unprotected groups have equal average predicted probability score . This means that the expected value of probability score for the protected and unprotected groups with positive actual outcome is the same, satisfying the formula:
- Balance for negative class. A classifier satisfies this definition if the subjects constituting the negative class from both protected and unprotected groups have equal average predicted probability score . This means that the expected value of probability score for the protected and unprotected groups with negative actual outcome is the same, satisfying the formula:
Algoritmos
Se puede aplicar la equidad al aprendizaje automático desde tres perspectivas: pre-procesando los datos utilizados en el algoritmo, optimizando los objetivos durante el entrenamiento o procesando las respuestas tras la ejecución del algoritmo.
Preprocesamiento
Los algoritmos que corrigen el sesgo mediante preprocesamiento intentan eliminar información sobre ciertos atributos de los datos que pueden provocar un comportamiento injusto de la IA, al mismo tiempo que tratan de alterar estos datos lo menos posible. Eliminar del conjunto de datos una variable protegida no es suficiente, ya que otras variables pueden estar correlacionadas con ella.
Una posible forma de hacerlo consiste en asociar cada individuo del conjunto de datos a una representación intermedia en la que sea imposible determinar si pertenece o no a un grupo protegido, a la vez que se mantiene el resto de la información tanto como sea posible. Después, se ajusta la nueva representación del conjunto de datos para buscando el máximo acierto del algoritmo.
De este modo, los individuos se vinculan a una nueva representación en la que la probabilidad de que un miembro de un grupo protegido sea asociado a cierto valor de la nueva representación es la misma que la de un individuo no protegido. Así, es la nueva representación la que se utiliza para obtener la predicción para el individuo en vez de los datos originales. Como la representación intermedia se ha construido dando la misma probabilidad a cada individuo independientemente de si pertenecen al grupo protegido o no, esto queda oculto para el clasificador.
Se puede encontrar un ejemplo en Zemel y otros [3] en el que se utiliza una variable aleatoria multinomial como representación intermedia. En el proceso, se preserva toda la información excepto la que pueda conducir a decisiones sesgadas a la vez que se busca una predicción lo más correcta que sea posible.
Por un lado, este procedimiento tiene la ventaja de que los datos preprocesados se pueden utilizar para cualquier tarea de aprendizaje automático. Además, no hay que modificar el código del clasificador, ya que la corrección se aplica a los datos que se van a introducir en él. Por otro lado, los otros métodos obtienen mejores resultados tanto en acierto como en equidad. [4]
Reweighing [5]
La técnica del reweighing, en español reasignación de pesos, es un ejemplo de algoritmo de preprocesamiento. La idea consiste en asignar un peso a cada punto del conjunto de datos de tal manera que la discriminación ponderada es 0 respecto al grupo de interés.
Si el conjunto de datos ![]() fuera no sesgado, la variable protegida
fuera no sesgado, la variable protegida ![]() y la variable objetivo
y la variable objetivo ![]() serían estadísticamente independientes y la probabilidad de la distribución conjunta sería el producto de las probabilidades de la siguiente manera:
serían estadísticamente independientes y la probabilidad de la distribución conjunta sería el producto de las probabilidades de la siguiente manera:
Sin embargo, en la vida real el conjunto de datos suele estar sesgado y las variables no son estadísticamente independientes por lo que la probabilidad observada es:
Para compensar el sesgo, se asignan mayores pesos a los puntos no favorecidos y menores a los favorecidos. Para cada ![]() obtenemos:
obtenemos:
Una vez tenemos asignado a cada ![]() un peso asociado calculamos la discriminación ponderada con respecto al grupo
un peso asociado calculamos la discriminación ponderada con respecto al grupo ![]() de la siguiente manera:
de la siguiente manera:

Se puede demostrar que después de la asignación de los pesos la discriminación ponderada es 0.
Optimización durante el entrenamiento
Otra aproximación al problema es corregir el sesgo durante el entrenamiento. Esto puede hacerse añadiendo restricciones al objetivo del algoritmo.[6] Estas restricciones obligan al algoritmo a tener en cuenta la equidad, de forma que el máximo éxito no sea su único objetivo, sino también mantener ciertas métricas iguales tanto para el grupo protegido como para el resto de individuos. Por ejemplo, se puede añadir al algoritmo la condición de que la tasa de falsos positivos sea la misma para individuos del grupo protegido y para los que no lo son.
Las principales métricas que se utilizan en esta técnica son la tasa de falsos positivos, la tasa de falsos negativos y la tasa general de fallo. Es posible añadir sólo una o varias de estas restricciones al objetivo. Nótese que la igualdad de las tasas de falsos negativos implica la igualdad también de las tasas de verdaderos positivos, lo que significa igualdad de oportunidad. Tras añadir las restricciones al algoritmo, el problema puede volverse infactible y por tanto puede ser necesario relajarlas.
Esta técnica obtiene buenos resultados al mejorar la equidad, al mismo tiempo que mantiene una exactitud alta, y permite al programador elegir las métricas que mejor se ajusten a sus necesidades. Sin embargo, la técnica y las métricas utilizadas varían en función del problema y es necesario modificar el código del algoritmo, lo que no siempre es posible.[4]
Adversarial debiasing [7] [8]

We train two classifiers at the same time through some gradient-based method (f.e.: gradient descent). The first one, the "predictor" tries to accomplish the task of predicting ![]() , the target variable, given
, the target variable, given ![]() , the input, by modifying its weights
, the input, by modifying its weights ![]() to minimize some loss function
to minimize some loss function ![]() . The second one, the "adversary" tries to accomplish the task of predicting
. The second one, the "adversary" tries to accomplish the task of predicting ![]() , the sensitive variable, given
, the sensitive variable, given ![]() by modifying its weights
by modifying its weights ![]() to minimize some loss function
to minimize some loss function ![]() .
.
An important point here is that, in order to propagate correctly, ![]() above must refer to the raw output of the classifier, not the discrete prediction; for example, with an artificial neural network and a classification problem,
above must refer to the raw output of the classifier, not the discrete prediction; for example, with an artificial neural network and a classification problem, ![]() could refer to the output of the softmax layer.
could refer to the output of the softmax layer.
Then we update ![]() to minimize
to minimize ![]() at each training step according to the gradient
at each training step according to the gradient ![]() and we modify
and we modify ![]() according to the expression:
according to the expression:
where ![]() is a tuneable hyperparameter that can vary at each time step.
is a tuneable hyperparameter that can vary at each time step.

The intuitive idea is that we want the "predictor" to try to minimize ![]() (therefore the term
(therefore the term ![]() ) while, at the same time, maximize
) while, at the same time, maximize ![]() (therefore the term
(therefore the term ![]() ), so that the "adversary" fails at predicting the sensitive variable from
), so that the "adversary" fails at predicting the sensitive variable from ![]() .
.
The term ![]() prevents the "predictor" from moving in a direction that helps the "adversary" decrease its loss function.
prevents the "predictor" from moving in a direction that helps the "adversary" decrease its loss function.
It can be shown that training a classification model "predictor" with this algorithm decreases demographic parity with respect to training it without the "adversary".
Post-procesamiento
La última técnica trata de corregir las respuestas del clasificador para alcanzar la equidad. En éste método, necesitamos hacer una predicción binaria para los individuos y tenemos un clasificador que devuelve una puntuación asociada a cada uno de ellos. Los individuos con puntuaciones altas tenderán a obtener una respuesta positiva, mientras que aquellos con una puntuación baja tendrán una respuesta negativa, pero necesitamos determinar el umbral a partir del cual se responde positiva o negativamente. Nótese que variar el umbral afecta al compromiso entre la tasa de verdaderos positivos y la tasa de verdaderos negativos, y en función del problema nos puede interesar mejorar una a costa de la otra.
Si la función de puntuación es justa, en el sentido de que es independiente del atributo protegido, entonces cualquier elección del valor umbral será también justa, pero este tipo de clasificadores tienden a sesgarse con facilidad, por lo que puede que necesitemos especificar un umbral distinto para cada grupo protegido. Una forma de hacerlo es estudiar las gráficas de la tasa de verdaderos positivos frente a la de verdaderos negativos para distintos valores del umbral (a esto se le conoce como curva ROC) y comprobar para qué valor del umbral las tasas son iguales para el grupo protegido y para el resto de individuos.[9]
Entre las ventajas del post-procesamiento están que la técnica se puede aplicar después de usar cualquier clasificador, sin necesidad de modificarlo, y obtiene buenos resultados mejorando métricas de equidad. Entre los inconvenientes, es necesario consultar el valor del atributo protegido durante el post-procesamiento y se restringe la libertad del programador para regular el compromiso entre equidad y exactitud.[4]
Reject Option based Classification (ROC) [10]
Given a classifier let ![]() be the probability computed by the classifiers as the probability that the instance
be the probability computed by the classifiers as the probability that the instance ![]() belongs to the positive class +. When
belongs to the positive class +. When ![]() is close to 1 or to 0, the instance
is close to 1 or to 0, the instance ![]() is specified with high degree of certainty to belong to class + or - respectively. However, when
is specified with high degree of certainty to belong to class + or - respectively. However, when ![]() is closer to 0.5 the classification is more unclear.
is closer to 0.5 the classification is more unclear.
We say ![]() is a "rejected instance" if
is a "rejected instance" if ![]() with a certain
with a certain ![]() such that
such that ![]() .
.
The algorithm of "ROC" consists on classifying the non rejected instances following the rule above and the rejected instances as follows: if the instance is an example of a deprived group ( ![]() ) then label it as positive, otherwise label it as negative.
) then label it as positive, otherwise label it as negative.
We can optimize different measures of discrimination as functions of ![]() to find the optimal
to find the optimal ![]() for each problem and avoid becoming discriminatory against the privileged group.
for each problem and avoid becoming discriminatory against the privileged group.
References
- ↑ 1,0 1,1 1,2 Solon Barocas; Moritz Hardt; Arvind Narayanan, Fairness and Machine Learning. Consultado el 15 de diciembre de 2019.
- ↑ 2,0 2,1 Sahil Verma; Julia Rubin, Fairness Definitions Explained. Consultado 15 December 2019
- ↑ Richard Zemel; Yu (Ledell) Wu; Kevin Swersky; Toniann Pitassi; Cyntia Dwork, Learning Fair Representations. Consultado el 1 de Diciembre de 2019
- ↑ 4,0 4,1 4,2 Ziyuan Zhong, Tutorial on Fairness in Machine Learning. Consultado el 1 de Diciembre de 2019
- ↑ Faisal Kamiran; Toon Calders, Data preprocessing techniques for classification without discrimination. Consultado el 17 de Diciembre de 2019
- ↑ Muhammad Bilal Zafar; Isabel Valera; Manuel Gómez Rodríguez; Krishna P. Gummadi, Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment. Consultado el 1 de Diciembre de 2019
- ↑ 7,0 7,1 Brian Hu Zhang; Blake Lemoine; Margaret Mitchell, Mitigating Unwanted Biases with Adversarial Learning. Retrieved 17 December 2019
- ↑ 8,0 8,1 Joyce Xu, Algorithmic Solutions to Algorithmic Bias: A Technical Guide. Retrieved 17 December 2019
- ↑ Moritz Hardt; Eric Price; Nathan Srebro, Equality of Opportunity in Supervised Learning. Retrieved 1 December 2019
- ↑ Faisal Kamiran; Asim Karim; Xiangliang Zhang, Decision Theory for Discrimination-aware Classification. Retrieved 17 December 2019